
Zero-knowledge proofs have become a core primitive for blockchain infrastructure, underpinning privacy, scaling, and secure interoperability. For layer-2 rollups in particular, ZK can be used to accelerate finality by eliminating the traditional 7-day challenge window.
Advances in zkVMs have made this practical. Teams can now generate proofs for real workloads and move from research to production far more quickly than before.
As a result, the bottleneck has shifted. The challenge is no longer whether rollups can generate proofs, but how proofs are generated and guaranteed in production: securely, reliably, and under worst-case conditions.
This forces every rollup team to confront the same question: how should proving be handled?
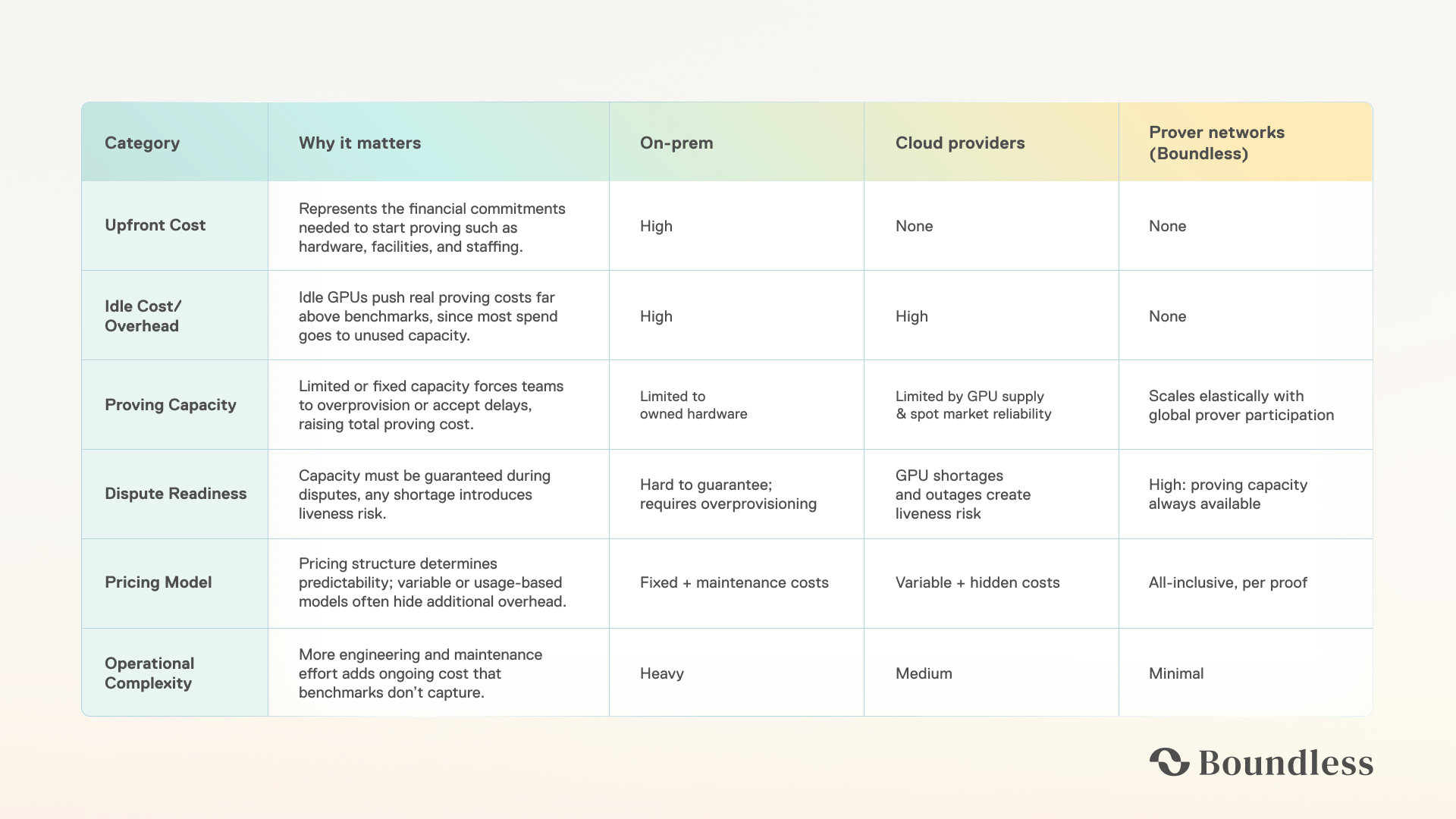
There are three ways to do it:
- Run your own hardware (on-prem)
- Use a cloud provider (AWS/GCP)
- Use a prover network (Boundless)
Most teams begin by comparing zkVM benchmarks on sites like ethproofs. However, these numbers only reflect the cost of generating a single proof under ideal conditions and neglect other significant costs that teams incur in production.
In production (whether you’re a full validity rollup or using zk fraud proofs) the real cost depends on how much capacity must be kept online, how redundant it needs to be, and who operates it. Once idle capacity, orchestration overhead, and availability risk are accounted for, the economics look very different from zkVM benchmarks.
Picking your Proving Infrastructure
1. On-prem
Running your own proving is objectively the most hands-on approach. You are effectively building and maintaining a data center.
That means designing the facility, sourcing GPUs, ensuring stable power and cooling, racking and networking hardware, and hiring data center technicians to keep it operational. To ensure high reliability you’ll need back-up power, plans to repair or replace damaged hardware, and around-the-clock monitoring to address any emerging issues or outages.
This level of control can appeal to teams with hardware experience and predictable workloads. You can tune performance precisely and operate independently of third parties, though your proving capacity is fixed by the hardware you have on the floor. If demand for your protocol suddenly spikes, you cannot scale proving dynamically without going through another full hardware procurement and deployment cycle.
You also assume every operational and capital expense, along with the downside risk. If your prover cluster goes down and you have no backup path, your protocol goes down too.
For high-throughput rollups, these costs escalate quickly. At production scale, the hardware required to sustain continuous proving can reach into the millions. For a rollup with throughput comparable to Base, GPU hardware alone can exceed $6.5M, before accounting for facilities, power, redundancy, or operational staffing.
2. Cloud providers
Many rollups start by running their proving infrastructure on cloud platforms like AWS. The appeal is straightforward: instead of owning hardware, you rent it and pay as you go.
In practice, cloud proving still requires reserving capacity in advance. GPUs are billed by the hour, whether they are actively proving or not.
Idle capacity dominates cost
To ensure proofs can be generated at any moment, a baseline prover cluster must remain online at all times. In the early days of RISC Zero’s self-hosted cloud clusters, over 90% of total spend came from idle GPUs, not from actual proving work.
Autoscaling helps, but only marginally:
- Baseline clusters must stay online to guarantee proving capacity
- GPUs remain active for minutes after jobs complete
- Reserved instances lock teams into months of fixed spend
- Spot instances are unreliable and frequently reclaimed during high-demand periods
Hidden costs
Beyond compute time, cloud proving introduces additional costs that benchmarks rarely capture. These include data transfer fees, RPC costs to fetch inputs, and provider markups. On AWS alone, these overheads add roughly 30% on top of raw GPU pricing.
Quotas limit scalability
Cloud providers also enforce strict service quotas that cap how many GPU instances you can run in each region. These quotas directly apply to the GPU families rollups rely on for proving. To exceed them, teams must file a quota-increase request, justify their usage, and wait for manual approval.
Higher quotas typically correlate with higher committed spend, but approval is not guaranteed. Even well-funded teams can be blocked from scaling when demand spikes.
For rollups that must scale instantly (especially during disputes) quota ceilings create a structural risk: even if you have the budget, additional capacity may not be available when you need it.
Cloud proving, in short, hides its real cost in capacity risk. You’re still responsible for keeping enough GPUs online at all times, whether they’re actively proving or not.
3. Prover networks
Prover networks change the model entirely. Instead of managing GPUs, rollups pay only for proofs that are successfully delivered.
Rollups submit proof requests through the Boundless API. Independent provers compete to fulfill them, and the network absorbs all of the idle, availability, and orchestration risk.
Predictable, all-inclusive pricing
Because costs are driven by market competition and not by idle infrastructure, prover networks offer the first pricing model that reflects actual proving work.
Boundless publishes its market pricing transparently on its explorer. Today, the median market-clearing cost for proving on Boundless is under $0.04 per billion cycles.
This price already includes the full cost of proving—hardware, redundancy, energy, and coordination. There are no additional overheads to account for.
Solving the capacity problem
A common misconception is that prover networks can’t provide enough capacity to handle generating fraud proofs during disputes. That may be true for smaller or permissioned systems. It’s not true for Boundless.
Boundless operates one of the largest decentralized proving markets in existence, sustaining 400 trillion cycles of available compute capacity per day.
This high amount of capacity exists because the network itself covers the cost of capacity through Proof of Verifiable Work (PoVW), a permissionless incentive mechanism that rewards provers for contributing proving work.
Even during low-demand periods, PoVW keeps the capacity active and ready. When disputes occur and demand spikes, that surplus capacity ensures proofs are completed without delay.
What this means for rollups
For OP rollups, this delivers two outcomes:
- Guaranteed liveness under disputes. Boundless’ high capacity ensures proofs are completed without delay, even during spikes in demand.
- Predictable economics. Rollups pay per proof, with no hidden costs. Pricing already accounts for infrastructure, redundancy, and coordination, removing the need to overprovision or plan for worst-case scenarios.
Key Takeaways
For rollups integrating ZK, understanding the real economics of proving is critical. Proving is not a benchmark problem, it is a capacity, liveness, and risk-allocation problem.
On-prem gives you control but comes with heavy CapEx and ongoing operational risk. However, teams that prefer to run their own infrastructure can still use Boundless as a redundancy layer to maintain liveness during downtime or maintenance.
Cloud providers offer convenience, but hide their true cost in idle capacity, scaling delays, and limited GPU availability. The unpredictability of cloud supply makes it difficult to guarantee capacity during disputes, an unacceptable risk for rollups that rely on proving capacity being available.
Prover networks are the only model that deliver all-inclusive pricing with guaranteed capacity. With Boundless, rollups get exactly what they pay for: proofs generated on-demand, with predictable costs and confidence that capacity will always be there when needed.
For OP rollups bringing ZK to production, Boundless is designed to make proving both economically and operationally predictable, scaling capacity with demand while removing the costs that cloud and on-prem solutions can’t escape.
If you’re a rollup team, get in touch to see how Boundless could work for you.
If you are a protocol looking to immediately start requesting proofs, learn more by visiting the Boundless documentation.